Mastering Image Scraping from Websites Using Python and GoProxy
Post Time: 2024-06-03Update Time: 2024-06-03
Everything you should know about using Python to scrap images...
Introduction
In today's digital age, images play a significant role in various applications, from e-commerce to computer vision. Python, coupled with GoProxy's powerful Residential Proxies, provides a robust framework for scraping images from websites efficiently. This blog will guide you through the process of scraping images from a website using Python, ensuring a seamless and effective workflow.
The process of the Image Scraping Process
Image scraping involves extracting images from targeted websites. Python provides a range of libraries, such as BeautifulSoup and Requests, which greatly simplify this process. GoProxy's Residential Proxies further enhance the scraping experience by ensuring anonymity and preventing IP blocking.
Setting Up the environment
To begin scraping images from websites, follow these steps:
1) Install Python: Download and install the latest version of Python from the official website.
2) Install Required Libraries: Use the pip package manager to install the necessary Python libraries, including BeautifulSoup, Requests, and Pillow. These libraries enable web scraping, HTTP requests, and image processing, respectively.
3) Obtain GoProxy Residential Proxies: Sign up for GoProxy's Residential Proxies and obtain your API access credentials.
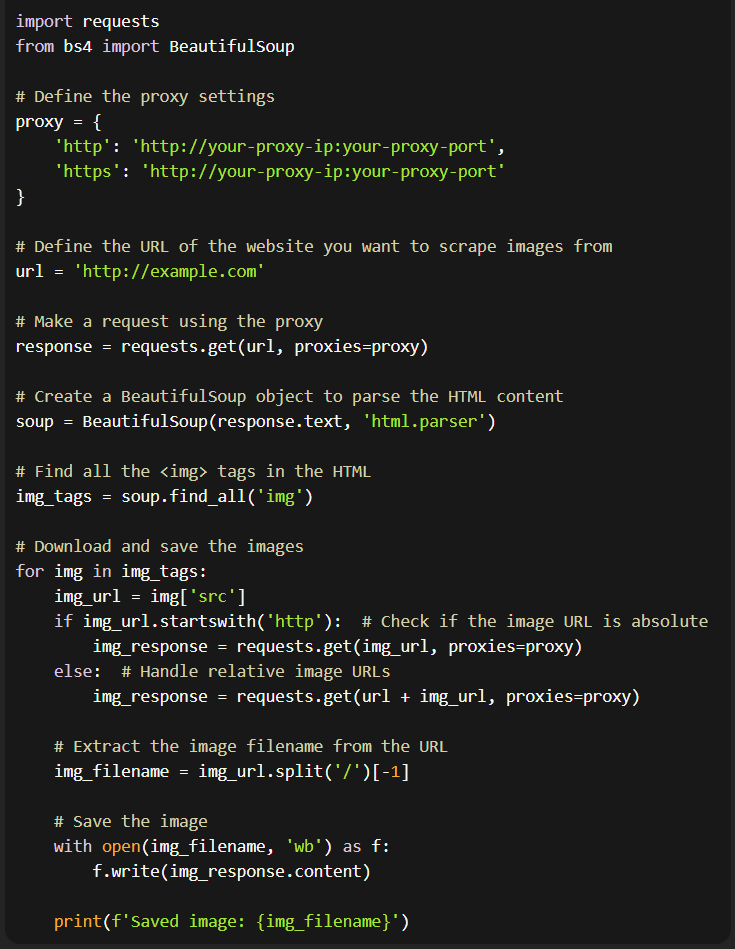
Scraping Images from Websites with Python
To scrape images from a website using Python, follow these steps:
1) Import Libraries: Import the required Python libraries, including BeautifulSoup and Requests.
2) Set Up GoProxy Residential Proxies: Configure your Python script to use GoProxy's Residential Proxies by specifying the proxy settings and providing the necessary authentication details.
3) Send HTTP Request: Use the Requests library to send an HTTP request to the target website and retrieve the webpage's HTML content.
4) Parse HTML: Utilize BeautifulSoup to parse the HTML content and extract the image URLs.
5) Download and Save Images: Iterate through the extracted image URLs, download the images using Requests, and save them to your local machine.
6) Optional: Perform Image Processing: If needed, you can use the Pillow library to perform image processing tasks, such as resizing, cropping, or applying filters to the downloaded images.
Handling Errors and Ensuring Compliance
When scraping images from websites, it's important to handle errors gracefully and adhere to ethical guidelines. Implement error-handling mechanisms to manage exceptions, timeouts, or invalid URLs. Respect the website's terms of service, robots.txt file, and copyright laws. Additionally, use GoProxy's Residential Proxies to ensure anonymity and prevent IP blocking.
Conclusion
Python, along with GoProxy's Residential Proxies, provides a powerful combination for effectively scraping images from websites. With Python's rich library ecosystem and GoProxy's secure and anonymous proxy servers, you can automate the image scraping process efficiently and legally. Remember to always respect website policies and legal boundaries when scraping images.
If you have any further questions or need assistance regarding image scraping with Python or the usage of GoProxy Residential Proxies, don't hesitate to reach out to our support team on our website: goproxy.com/en/contact. We're here to help you succeed in your image-scraping endeavors.
Key Features:
Excellent customer support
Easy to set up for your project, scrapers, APIs, actors
Smart IP address rotation
< Previous
Unlock Real-Time Crypto Insights: Why Every Trader Needs a Telegram Proxy
Next >
How to find intended audience on Instagram by niche?