Tired of getting blocked when your scraper hits Amazon’s Buy Box page? Frustrated by missing the true, geo-specific price or seller because your HTML fetch came up empty? Whether you’re an ecommerce analyst tracking competitor pricing, a seller optimizing your Buy Box strategy, or a data scientist building market intelligence tools, this guide will help you reliably extract Amazon Buy Box data at scale. It shows two core approaches to extract Buy Box title, price, seller, and availability using GoProxy’s residential proxies, so you can choose the right path for your team’s needs.
What Is the Amazon Buy Box—and Why Scrape It?
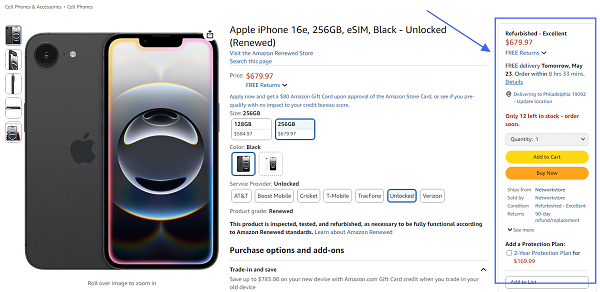
The Buy Box is the section on an Amazon product page where customers can add items to their cart or buy now, typically showing the seller who has won the Buy Box, along with price, shipping information, and availability.
Over 80% of transactions flow through it, so:
- Competitive Intelligence: Track who wins the Buy Box and at what price.
- Dynamic Pricing: Adjust your strategy based on real-time competitor moves.
- Market Research: Analyze stock levels and promotions across multiple ASINs.
Core Challenges in Buy Box Scraping
Scraping Amazon’s Buy Box comes with hurdles:
Anti-Scraping Defenses
Amazon enforces rate limits, IP bans, and CAPTCHAs to deter bots.
Geo-Specific Variations
Buy Box winners and prices differ by region—U.S., U.K., DE, JP, etc.
Dynamic Loading
Elements like price and seller info may load via JavaScript/AJAX.
Session Requirements
Some data (e.g., Prime eligibility) needs cookies or authenticated sessions.
You’ll need proxy rotation, page rendering, or managed services to tackle these.
Prerequisites & Setup
1. Provision Your Tools
GoProxy Rotating Residential Proxies
Sign up here and note your endpoints (USER:PASS@HOST:PORT) across target regions.
GoProxy Web Scraping Service (Optional)
For fully managed scraping, request access to our custom web scraping service and retrieve your API_KEY.
2. Install Dependencies
Python 3.8+
Libraries: requests, beautifulsoup4, playwright
bash
pip install requests beautifulsoup4 playwright
playwright install
3. Prepare Your ASIN List
Gather the ASINs (Amazon Standard Identification Numbers) you want to scrape.
Method 1. Using Web Scraping Services
GoProxy’s Web Scraping Service provides an API that handles proxies, CAPTCHAs, and JavaScript rendering for you. It’s perfect for teams wanting a low-effort, high-reliability solution.
1. Define Your Scrape Job
Send a POST request with your target URL and selectors.
http
POST https://api.goproxy.com/scrape
Authorization: Bearer YOUR_API_KEY
Content-Type: application/json
{
"url": "https://www.amazon.com/dp/B08N5WRWNW",
"selectors": {
"title": "#productTitle",
"price": "#corePrice_feature_div .a-offscreen",
"seller": "#sellerProfileTriggerId",
"availability": "#availability span"
},
"features": {
"rotate_proxies": true,
"render_js": true,
"solve_captcha": true
}
}
2. Parse the Response
{
"title": "Wireless Bluetooth Headphones",
"price": "$49.99",
"seller": "TopSeller Inc.",
"availability": "In Stock."
}
Method Pros & Cons
Pros: No setup, auto-handles proxies and CAPTCHAs, renders JavaScript.
Cons: Higher cost at scale, less customization.
Delegate complexity to GoProxy Web Scraping Service! We handle proxy rotation, CAPTCHA solving, and JavaScript rendering. Ideal for teams without in-house scraping infrastructure. Contact us to get your custom plan today!

Method 2. Building a Custom Scraper
A custom scraper gives you full control and flexibility, ideal for technical teams willing to manage their own setup.
1. Define Buy Box Selectors
Confirm these CSS selectors:
- Title: #productTitle
- Price: #corePrice_feature_div .a-offscreen
- Seller: #sellerProfileTriggerId
- Availability: #availability span
2. Rotate Proxies & Fetch Page
Use residential proxies to avoid IP bans and geo-variations:
python
import random
import requests
from bs4 import BeautifulSoup
PROXIES = [
"http://USER:[email protected]:8000",
"http://USER:[email protected]:8000",
# Add more as needed
]
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/124.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9"
}
def fetch_page(asin):
url = f"https://www.amazon.com/dp/{asin}"
proxy = {"http": random.choice(PROXIES), "https": random.choice(PROXIES)}
resp = requests.get(url, headers=HEADERS, proxies=proxy, timeout=15)
resp.raise_for_status()
return resp.text
3. Check for Dynamic Content
If selectors aren’t in the HTML, JavaScript rendering is needed.
python
def needs_render(html):
return not any(sel in html for sel in ["corePrice_feature_div", "sellerProfileTriggerId"])
4. Render with Playwright
Use a headless browser for dynamic pages.
python
from playwright.sync_api import sync_playwright
def render_page(asin):
with sync_playwright() as p:
proxy = random.choice(PROXIES).replace("http:/", "")
browser = p.chromium.launch(headless=True, proxy={"server": proxy, "username": "USER", "password": "PASS"})
page = browser.new_page()
page.goto(f"https://www.amazon.com/dp/{asin}", wait_until="networkidle")
content = page.content()
browser.close()
return content
5. Parse Buy Box Data
Extract data from static or rendered HTML.
python
def parse_buy_box(html, asin):
soup = BeautifulSoup(html, "html.parser")
return {
"asin": asin,
"title": soup.select_one("#productTitle").get_text(strip=True) if soup.select_one("#productTitle") else "N/A",
"price": soup.select_one("#corePrice_feature_div .a-offscreen").get_text(strip=True) if soup.select_one("#corePrice_feature_div .a-offscreen") else "N/A",
"seller": soup.select_one("#sellerProfileTriggerId").get_text(strip=True) if soup.select_one("#sellerProfileTriggerId") else "N/A",
"availability": soup.select_one("#availability span").get_text(strip=True) if soup.select_one("#availability span") else "N/A"
}
6. Add Retries & Error Handling
Wrap fetch/render in retry logic to handle timeouts, bans, and CAPTCHAs:
python
import time
def get_buy_box(asin, max_retries=3):
for attempt in range(max_retries):
try:
html = fetch_page(asin)
if needs_render(html):
html = render_page(asin)
return parse_buy_box(html, asin)
except Exception as e:
print(f"Attempt {attempt+1} failed: {e}")
time.sleep(2 ** attempt)
return {"asin": asin, "error": "Failed after retries"}
7. Store & Schedule
Storage: Append results to CSV or insert into a database (PostgreSQL, MongoDB).
Scheduling: Use cron or Airflow to run get_buy_box() every 10–30 minutes for each ASIN.
Method Pros & Cons
Pros: Fully customizable, cost-effective at scale.
Cons: Requires setup and maintenance.
Check our customer case of Amazon buy box scraping here.
Best Practices & Ethical Considerations
- Follow Rules: Respect Amazon’s robots.txt and Terms of Service.
- Throttle: Add 2–5 second delays between requests.
- Rotate: Use varied user-agents and proxies.
- Monitor: Log proxy performance and retire failing IPs.
- Secure: Keep credentials in environment variables.
- Audit: Save raw HTML and results for compliance.
Legal Note: Scraping public data (prices, sellers) is typically fine, but avoid server overload or personal data. Check local laws and consult experts.
Troubleshooting Common Issues
1. Blocked Scraper
Increase proxy rotation. Add random delays. Switch user-agents.
2. Missing Data
Verify selectors manually. Render with Playwright.
3. CAPTCHAs
Retry with a new proxy. Use a CAPTCHA-solving service.
4. Wrong Region Data
Confirm proxy region settings.
Final Thoughts
Whether you choose GoProxy’s managed API or a custom scraper, scraping Amazon Buy Box data is achievable with the right tools and practices. Use this guide to build a reliable, ethical workflow that delivers actionable insights for pricing, competition, and market trends.
Get Started?! 7-day rotating residential proxy free trial to fully experience for trust. Sign up to get it today! Or unlimited rotating residential proxy plans for scale demand. Real unlimited traffic, one-hour trial!











