
How to Use Whoer IP for IP Checks: A Step-by-Step Guide
Discover how to use Whoer.net to check and verify your IP address. Explore top alternatives for comprehensive IP management .
Apr 2, 2026



A step-by-step guide on Amazon web scraping with Python, proxy strategies, legal tips, and scaling advice. Learn how to extract product data, pricing, reviews, etc.
Web scraping Amazon can provide real-time access to product data, pricing trends, reviews, etc. However, doing it effectively requires some techniques, such as handling anti-scraping measures and dynamic content. There is also a common concern about its legality.
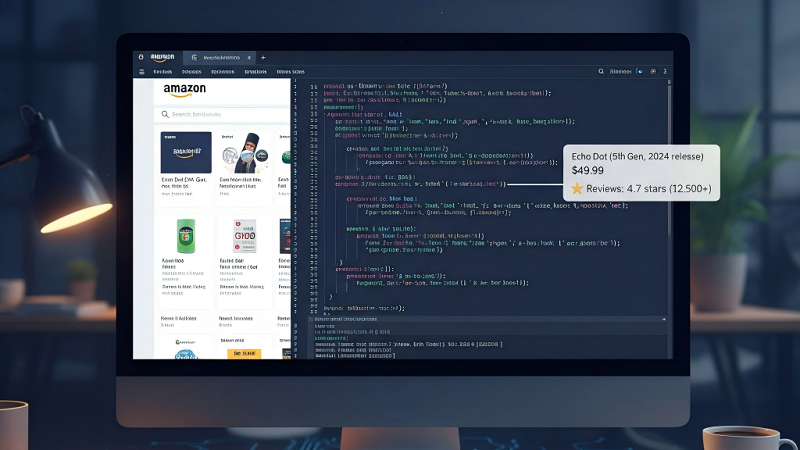
This guide will walk you through the entire process, starting from basic scraping scripts to advanced techniques such as using proxies and headless browsers for scaling, covering practical steps and legal considerations.
As the world's largest online retailer, Amazon is a data treasure for businesses and researchers. Scraping its data can help:
Price monitoring: Track competitor pricing and adjust the pricing strategy in real-time.
Product research: Analyze trends, sentiment from reviews, and inventory levels.
Market analysis: Collect data on rankings, best-sellers, product categories, and seller performance.
Different projects have specific needs. For example, in terms of data amount, small retailers monitor the prices of 10–1,000 products, while analytics or machine learning may need hundreds of thousands of product pages. You need to adjust the scraping strategy accordingly.
Web scraping publicly available data on Amazon is generally legal in most jurisdictions, provided you’re not accessing private data (e.g., user accounts) or overloading Amazon’s servers. However, it typically violates Amazon’s Terms of Service (TOS), which prohibit automated access.
Consequences: Small-scale scrapers may face IP or account bans. Amazon typically blocks your IP if it detects automated scraping. For larger operations, risks include cease-and-desist letters or lawsuits if data is used competitively.
Fair Use: In the LinkedIn vs. hiQ case (2019, with ongoing relevance), courts ruled in favor of scraping publicly available data under fair use, but Amazon uses aggressive technical anti-scraping.
Commercial Use: For scraping large-scale data for business purposes, it’s wise to consult legal counsel to understand potential risks, especially under data privacy laws like GDPR or CCPA.
Disclaimer: This guide is for educational purposes only. Web scraping may violate Amazon's TOS and could lead to IP bans, account restrictions, or legal issues. Always consult a legal professional before using scraped data commercially, and consider alternatives like Amazon's official APIs.
Before you begin scraping, make sure to:
Only collect public data: Avoid scraping login pages or private user information.
Check Amazon’s robots.txt: Evaluate their API options and consider using them for compliant access.
Rate-limit your requests: Avoid overloading Amazon's servers by simulating human behavior with random delays.
Log key metadata: Include URL, timestamp, headers, and proxy information for transparency.
Consult legal counsel for commercial scraping projects.
We'll use Python for this guide because it’s free, versatile, and easy to learn. Professionals can also scale this solution to run in the cloud for larger datasets.
First, download and install Python from python.org. Verify the installation by running:
python --version
We will use the following libraries for scraping and parsing HTML:
pip install requests beautifulsoup4 lxml pandas playwright selenium
python -m playwright install
Tip for Beginners: Use a virtual environment (e.g., python -m venv myenv; source myenv/bin/activate) to keep dependencies isolated. If you encounter installation errors, check your Python version or pip permissions.
Below is a hardened beginner scraper that adds retries, random user-agent rotation, and polite delays between requests. This script extracts the product name, price, rating, and ASIN (Amazon Standard Identification Number).
import re
import time
import csv
from random import choice, uniform
import requests
from bs4 import BeautifulSoup
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.0 Safari/605.1.15"
]
RETRY_STRAT = Retry(total=3, backoff_factor=1, status_forcelist=(429, 500, 502, 503, 504))
def build_session():
s = requests.Session()
s.headers.update({"Accept-Language": "en-US,en;q=0.9"})
adapter = HTTPAdapter(max_retries=RETRY_STRAT)
s.mount("https:/", adapter)
s.mount("http:/", adapter)
return s
def extract_asin(url, soup):
meta = soup.select_one("input#ASIN")
if meta and meta.get("value"):
return meta["value"]
m = re.search(r"/(?:dp|gp/product)/([A-Z0-9]{10})", url)
return m.group(1) if m else None
def parse(html, url):
soup = BeautifulSoup(html, "lxml")
title = soup.select_one("#productTitle")
price = soup.select_one(".a-price .a-offscreen") or \
soup.select_one("#corePrice_feature_div .a-price-whole") or \
soup.select_one("#priceblock_dealprice")
rating = soup.select_one(".a-icon-alt") # e.g., "4.5 out of 5 stars"
review_count = soup.select_one("#acrCustomerReviewText")
return {
"asin": extract_asin(url, soup),
"title": title.get_text(strip=True) if title else None,
"price_raw": price.get_text(strip=True) if price else None,
"rating": rating.get_text(strip=True).split(" out")[0] if rating else None,
"review_count": review_count.get_text(strip=True).split(" ")[0] if review_count else None
}
def main(urls):
s = build_session()
out = []
for u in urls:
s.headers["User-Agent"] = choice(USER_AGENTS)
try:
r = s.get(u, timeout=20)
r.raise_for_status()
out.append(parse(r.text, u))
except requests.RequestException as e:
print("Request failed:", u, e)
time.sleep(uniform(3, 6))
with open("products.csv", "w", newline='', encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["asin", "title", "price_raw", "rating", "review_count"])
writer.writeheader()
writer.writerows(out)
if __name__ == "__main__":
test_urls = ["https://www.amazon.com/dp/B0CRCWCGNW"] # Replace with your test URLs
main(test_urls)
Beginner Tips
Start small: Test with 5–20 URLs.
Monitor HTTP status codes (e.g., 200 for success, 503 for blocks) and ensure parsing success.
Save metadata like the timestamp and source URL for better troubleshooting.
If you get a 403 error, add a proxy (see Step 3). For missing data, inspect the page in your browser to verify selectors.
Before starting, it’s important to define what you want to scrape. Amazon product pages contain various types of data, including:
Product Pages: Detailed product information, such as title, price, description, etc.
Search Result Pages: Lists of products, useful for bulk data collection like prices and names.
Amazon's anti-bot systems (like CAPTCHAs and IP bans)
Frequent HTML changes
Some data (e.g., reviews) loads via JavaScript
Tip:
Before scraping, use browser developer tools (F12) to inspect the page’s HTML structure and identify CSS selectors for the data you want to extract (e.g., #productTitle for product names or .a-price for prices).
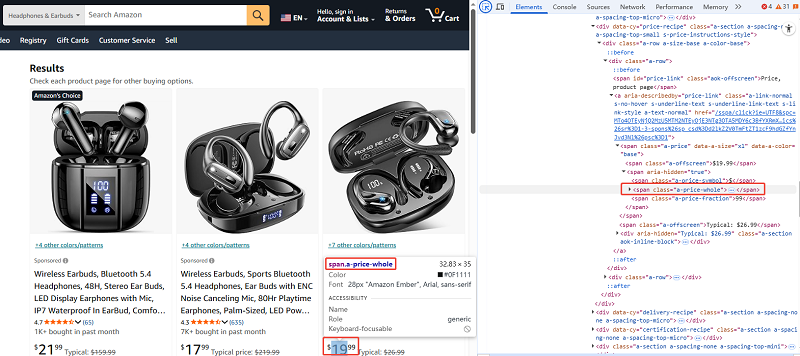
For beginners, practice on a static page first.
If selectors fail, Amazon may have updated the layout—re-inspect and update your code.
To begin scraping, you’ll first need to retrieve the HTML content of the Amazon page using an HTTP GET request. Amazon detects bots, so simulate a legitimate browser request with appropriate headers (like User-Agent and Accept-Language).
import requests
from bs4 import BeautifulSoup
url = "https://www.amazon.com/dp/B0CRCWCGNW" # Replace with your product URL
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9"
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status() # Raise error for bad status
html_content = response.text
except requests.RequestException as e:
print(f"Error fetching page: {e}")
User-Agent: Mimics a real browser to bypass basic bot detection.
Accept-Language: Sets locale to avoid suspicion.
Tips:
Basic requests may trigger blocks; add retries as in the quick-start.
Rotate User-Agents from a list for variety.
429/503? Slow down or add proxies (next step). For timeouts, increase timeout=30.
Proxies distribute requests across IPs; necessary for medium/large scrapes. GoProxy offers datacenter, residential, and mobile options; start with rotating residential for better evasion, balancing cost.
| Type | Description | Best For | Drawbacks |
| Datacenter | Fast, cheap servers not tied to ISPs | Small-scale testing | Easily detected |
| Residential | Real home IPs, harder to detect | Medium/large scrapes | Slower, more expensive |
| Mobile | Cellular IPs, very evasive | High-risk anti-bot sites | Costly, variable speed |
proxies = {
"http": "http://username:[email protected]:port", # From your provider dashboard
"https": "https://username:[email protected]:port"
}
response = requests.get(url, headers=headers, proxies=proxies)
GoProxy offers rotating proxies with sticky sessions(a session that sticks to one IP for a set time for consistent flows), can up to 60 minutes & customized to 120 minutes.
Tips:
When rotating, isolate cookies per proxy. Use one requests.Session() per proxy or clear cookies between switches.
Benchmark latency (time.perf_counter()) per proxy to understand costs and performance.
Once you have the HTML content, the next step is to parse it to navigate the structure (Parsing converts HTML to a searchable tree), and you will need using a library like BeautifulSoup.
soup = BeautifulSoup(response.text, 'lxml') # Faster parser
It simplifies finding elements via tags, classes, or IDs.
Tip:
Print soup.prettify() for debugging.
Parsing errors? Ensure 'lxml' is installed. If HTML is incomplete, it's likely JS-loaded(Step 7).
Here comes the key part of scraping—extracting data from the parsed HTML. Target elements using selectors. Here's how for common data:
The product title is typically located in an element with the ID productTitle.
title = soup.select_one("#productTitle")
product_name = title.get_text(strip=True) if title else "Not Available"
Product ratings can be found in the span[data-asin] or #acrPopover.
rating = soup.select_one(".a-icon-alt")
product_rating = rating.get_text(strip=True).split(" out")[0] if rating else "Not Available"
The price is found in different selectors, such as .a-price .a-offscreen, #priceblock_ourprice, or #priceblock_dealprice.
price = soup.select_one(".a-price .a-offscreen") or \
soup.select_one("#corePrice_feature_div .a-price-whole")
product_price = price.get_text(strip=True) if price else "Not Available"
Product images are often stored in JSON-LD or within the #landingImage element.
import re
image_pattern = r'"hiRes":"(.+?)"'
image_urls = re.findall(image_pattern, response.text)
product_image = image_urls[0] if image_urls else "No image found"
The product description is typically found in the #productDescription section.
description = soup.select_one("#feature-bullets") or soup.select_one("#productDescription")
product_description = description.get_text(strip=True) if description else "Not Available"
Review count and rating often appear in a span[data-asin] or similar tags.
reviews = soup.select_one("#acrCustomerReviewText")
review_count = reviews.get_text(strip=True).split(" ")[0] if reviews else "No reviews"
Tips:
Amazon’s HTML structure may update frequently, so it’s important to monitor selector changes regularly.
Handle variants by scraping variation links
Data missing? Re-inspect page—Amazon A/B tests layouts. For reviews, full extraction may need the reviews page URL.
Search results can span pages; loop with delays to avoid detection.
import time
import random
data = []
for page in range(1, 6): # Scrape first 5 pages
url = f"https://www.amazon.com/s?k=laptop&page={page}"
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# Extract data as in Step 5 and append to data list
time.sleep(random.uniform(2, 5)) # Random delay
Tip:
Too many pages trigger bans—rate-limiting(controlling request speed) is key. Always include randomized delays.
Pagination fails? Check if "&page=" works for your query. 503 error? Increase delay or add proxies.
Amazon loads prices/reviews via JS. Use headless browsers (automated browsers without UI). Playwright is faster than Selenium.
For simple pages, stick to Requests. For JS: Install as in prerequisites, then:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
context = browser.new_context(proxy={"server": "http://your-proxy:port"})
page = context.new_page()
page.goto(url, wait_until="networkidle")
title = page.locator("#productTitle").inner_text()
# Extract other elements similarly
context.close()
browser.close()
Playwright can handle JavaScript-rendered content and interact with dynamic pages, especially useful for price scraping and review mining when content is dynamically loaded.
Tips:
Create a new browser context per proxy/session.
Add randomized waits after navigation.
Do not disable JS or other browser features Amazon expects.
Blocks? Add fingerprinting (vary viewport/timezone). For beginners: Test on non-JS pages first.
Amazon has advanced anti-scraping mechanisms, such as CAPTCHAs, IP bans, and rate-limiting. Here's how you can deal with them:
Rotate User-Agent, Accept-Language, Referer.
Randomize delays with jitter; occasional longer sleeps.
Isolate cookies/local storage per proxy/session.
Use sticky sessions for multi-page flows.
Vary viewport and timezone in browser contexts.
Prefer JSON-LD fallback when HTML changes.
Exponential backoff (definition: increasing delays after failures) for 429/503; switch proxy after repeats.
Detection: Image puzzles, "To discuss automated access," or 429/503 with challenges.
Mitigation (Prevention First): Slow down, increase jitter, rotate proxies.
Scenarios: If blocked mid-scrape, pause 10-30 min and retry with new IP. For persistent issues, use residential proxies.
Advanced Options: Human-in-the-loop (manual solve), or third-party solvers (ethical/legal note: use sparingly; may violate TOS).
Tips:
CAPTCHAs is evolving, prevention > solving.
Monitor rates; if >1% CAPTCHA, investigate.
Ethical reminder: Avoid automation that harms sites.
After scraping, you need to store and manage the data you’ve collected. Use Pandas to structure and save to CSV; databases for scale.
import pandas as pd
df = pd.DataFrame({'Product Name': product_names, 'Price': prices}) # From your extractions
df.to_csv('amazon_products.csv', index=False, encoding="utf-8")
For deduplication (removing duplicates): Use ASIN as key.
df.drop_duplicates(subset=['asin'], inplace=True)
For larger sets: Use SQLite.
import sqlite3
conn = sqlite3.connect('amazon.db')
df.to_sql('products', conn, if_exists='replace')
Tips:
Add metadata (extraction_time, source_url, proxy_id, response_code). Store raw HTML for audits.
CSV encoding issues? Use 'utf-8'. Duplicates? Query by ASIN in DB.

As your scraping project grows, you need to think about scaling and monitoring to manage larger datasets and handle failures efficiently.
| Scale Level | Pages/Month | Tools/Setup | Rate | Cases |
| Small | ≤5k | Requests + BS4, single proxy, one VM | 1 req/3-10s per IP | Hobbyist tracking 100 products: Local script with delays. |
| Medium | 5k–100k | Rotating residential proxies, headless for JS, queue (Redis/RabbitMQ), DB (Postgres/Mongo) | Monitor errors | SMB price monitoring: AWS EC2 workers, auto-proxy rotation. |
| Large | 100k+ | Proxy fleet (residential/mobile), autoscaling workers (e.g., AWS Lambda/Kubernetes), fingerprint mitigation | Distributed | Enterprise ML training: Google Cloud VMs, session mapping, human-review for flags. |
Cloud Examples: Deploy on AWS Lambda for serverless (trigger via cron); use Azure Functions for auto-scaling. Example: Wrap script in Lambda, use S3 for storage.
For scaling demand, GoProxy offers unlimited rotating residential plans with real unlimited traffic from $72.50
/Day, perfect for enterprise-level projects. Experience one hour for only $20(sign up and get it).
requests_total, requests_per_min
parse_success_ratio = parses / requests
captcha_rate = captcha_pages / requests
proxy_error_rate per proxy
avg_latency_ms
Alert if captcha_rate >1% or parse_success <90%. Use Prometheus+Grafana.
Tips:
Automate maintenance with selector tests.
Scaling fails? Start with cloud free tiers.
Confirm pages are public and not behind login.
Test with 5–20 URLs and log everything.
Add retry/backoff and per-request metadata (proxy_id, UA, timestamp).
Use one proxy per browser context for headless.
Add exponential backoff for 429/503 and pause for high CAPTCHA rates.
Keep data provenance for audits.
Common Mistakes to Avoid: No delays (leads to bans), ignoring selector changes, scraping private data, poor error handling (e.g., no try-except for missing elements).
Q: Is scraping Amazon legal?
A: Collecting public info is not automatically illegal, but it can violate Amazon’s TOS and result in IP bans or restrictions. For commercial use, consult counsel and favor official APIs.
Q: Which proxy type should I choose?
A: For low volumes, datacenter or single proxy may suffice. For medium-to-large, rotating residential or mobile reduce blocks.
Q: How many requests per IP is safe?
A: No universal number—start low (1 req/3–10s per IP) and monitor with jitter.
Detection is strengthening in 2025–2026. Expect residential/mobile proxies and AI fingerprints as baselines.
Ballpark costs: Hobby <$50/month; SMB (1k–10k pages) $100–$1,000/month; enterprise (100k+) $2k–$20k+/month.
By following this comprehensive guide, you’ll be able to scrape Amazon efficiently—whether gathering product data, pricing trends, or reviews. With tools like proxies, headless browsers, and rate-limiting, you can scale while avoiding detection. Always respect Amazon’s TOS and maintain ethical practices to minimize risk.
< Previous
Next >







 Cancel anytime No credit card required
Cancel anytime No credit card required